| Identification |
| Name: |
Glutamate synthase [NADPH] large chain |
| Synonyms: |
- Glutamate synthase subunit alpha
- GLTS alpha chain
- NADPH-GOGAT
|
| Gene Name: |
gltB |
| Enzyme Class: |
|
| Biological Properties |
| General Function: |
Involved in catalytic activity |
| Specific Function: |
2 L-glutamate + NADP(+) = L-glutamine + 2- oxoglutarate + NADPH |
| Cellular Location: |
Not Available |
| KEGG Pathways: |
- Alanine, aspartate and glutamate metabolism pae00250
- Metabolic pathways pae01100
- Microbial metabolism in diverse environments pae01120
- Nitrogen metabolism pae00910
|
| KEGG Reactions: |
|
| SMPDB Reactions: |
|
2 L-Glutamic acid | + |  | + | 2 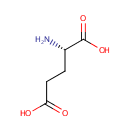 | → | 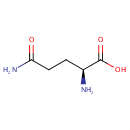 | + | NADPH | + |  | + | 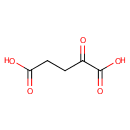 | + | 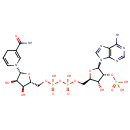 |
| | |
| + | | + | NADPH | + | | + | | → | 2 L-Glutamic acid | + | | + | 2 |
| |
|
| PseudoCyc/BioCyc Reactions: |
|
| Complex Reactions: |
Not Available |
| Transports: |
Not Available |
| Metabolites: |
|
| GO Classification: |
| Function |
|---|
| catalytic activity | | glutamate synthase activity | | oxidoreductase activity | | oxidoreductase activity, acting on the CH-NH2 group of donors | | Process |
|---|
| cellular amino acid and derivative metabolic process | | cellular amino acid metabolic process | | cellular metabolic process | | glutamate biosynthetic process | | glutamate metabolic process | | glutamine family amino acid metabolic process | | metabolic process | | nitrogen compound metabolic process | | oxidation reduction |
|
| Gene Properties |
| Locus tag: |
PA5036 |
| Strand: |
- |
| Entrez Gene ID: |
881222 |
| Accession: |
NP_253723.1 |
| GI: |
15600229 |
| Sequence start: |
5667696 |
| Sequence End: |
5672141 |
| Sequence Length: |
4445 |
| Gene Sequence: |
>PA5036
ATGAAAGCAGGTCTGTACCATCCTGAAACGTTCAAGGATAACTGCGGATTTGGCCTGATCGCCCATATGCAGGGCGAGCCGAGCCATCAACTTCTGCAAACCGCAATCGAAGCACTGACCTGCATGACCCACCGCGGTGGGATCAATGCCGATGGCAAGACCGGGGACGGCTGCGGGCTGCTGATCCAGAAGCCCGACCTGTTCCTGCGTGCCGTCGCCAGGGAAGCCTTTTCTGTCGACCTGCCCGAGCAATACGCGGTGGGCATGGTGTTCTTCAACCAGGACCCGGTGAAAGCCGAGGCGGCACGCGAGAACATGAATCGCGAGATCGTCGCCGCCGGACTGGAGCTGGTCGGCTGGCGCAAGGTGCCGATCGATACCAGCGTTCTCGGCCGCCTGGCGCTGGAGCGCCTGCCGCAGATCGAACAGGTGTTCATCGGCGGCGCCGGCCTGAGCGACCAGGACTTCGCCATCAAGCTGTTCAGCGCACGGCGCCGCTCGTCGGTGGCCAACGCCGCCGACAGCGACCACTACATCTGCAGCTTTTCGCACAAGACCATCATCTACAAGGGCCTGATGATGCCGGCCGACCTGGCCGCCTTCTATCCGGACCTTGGCGACGAGCGCCTGCAGACCGCGATCTGCGTATTCCACCAGCGCTTCTCCACCAACACCCTGCCGAAATGGCCGCTGGCGCAGCCGTTCCGCTTCCTCGCCCACAACGGCGAGATCAACACCATCACCGGCAACCGCAACTGGGCCCAGGCGCGGCGGACCAAGTTCACCAACGAACTGATCCCCGACCTGGAAGAGCTCGGCCCGCTGGTGAACCGCGTCGGCTCCGACTCGTCGAGCATGGACAACATGCTCGAACTGATGGTCACCGGCGGCATGGACCTGTTCCGCGGCCTGCGCATGATCATCCCGCCGGCCTGGCAGAACGTCGAAACCATGGACGCCGACCTGCGCGCGTTCTACGAGTACAACTCGCTGCACATGGAGCCCTGGGATGGCCCCGCCGGCGTCGTGCTGACCGACGGTCGCTATGCCGTCTGCCTGCTCGACCGCAATGGCCTGCGCCCGTCGCGCTGGGTCACCACGAAGAACGGCTACATCACCCTGGCTTCGGAAATCGGCGTCTGGGACTACAAGCCCGAGGACGTCATCGCCAAGGGTCGCGTCGGCCCGGGGCAGATCCTCGCGGTGGACACCGAGACCGGCCAGGTCCTGCACAGCGACGACATCGACAACCGCCTGAAGTCGCGCCATCCCTACAAGCAGTGGCTGCGGCAGAATGCCCTGCGCATCCAGGCGACCCTGGACGACGACCATGGCGTGGCCAGCTACGACGCCGACCAGCTCAAGCAATTCATGAAGATGTTCCAGGTCACCTTCGAGGAGCGTGACCAGGTGCTGCGTCCGCTCGGCGAGCAGGGCCAGGAAGCGGTGGGCTCCATGGGCGACGATACGCCGATGGCGATCCTCTCCCGGCGCATCCGCTCTCCGTACGATTACTTCCGCCAGCAATTCGCCCAGGTCACCAACCCGCCGATCGACCCGCTGCGCGAAGCCATCGTGATGTCCCTGGAAACCTGCCTGGGCGTCGAGCAGAACATCTTCGAGGAAGCCCCGCACCATGCCAACCAGGCGATCCTCACCACTCCGGTGATCTCGCCGGCGAAGTGGCGGACCATCATGACCCTGGACCGCCCGGGCTTCGACCGCCACTTCATCGACCTCAACTACGACGAGTCGATGGGCCTGGAGGCCGCGGTGCGCAACATCGCCGACCAGGCCGAGGAGGCCGTGCGCGGCGGCAAGGTGCTGCTGATCCTCAGCGACCGCCATATCGCTCCCGGCAAACTGCCGGTGCATGCTGCCCTGGCCGTCGGCGCGGTGCATCACCGCCTGGTGCAGACCGGGCTGCGCTGCGACTCCAACATCCTGGTGGAGACCGCCACCGCCCGCGATCCGCACCATTTCGCGGTGCTGATCGGCTTCGGCGCCTCGGCGGTCTATCCGTTCCTCGCCTACGAGGTGCTGGCCGACCTGATCCGCACCGGTGAAGTGCTGGGCGACCTCTACGAGGTGTTCAAGTACTACCGCAAGGGGATCTCCAAGGGCCTGATGAAGATTCTCTCGAAGATGGGCATCTCCACCGTCGCGTCCTACCGTGGCGCGCAGCTGTTCGAGGCGGTGGGCCTGTCCGACGAGGTCACCGACCTGTGCTTCACCGGAGTCGCCAGCCGCATCCAGGGCGCGCGCTTCGTCGATATCGAGAACGAGCAGAAGCTCCTGGCCGCCGAGGCCTGGAGCAACCGCAAGCCGATCCAGCAGGGCGGCTTGCTGAAGTTCGTCTATGGCGGCGAATACCACGCCTACAACCCGGATGTGGTGAATACCCTGCAGGCTGCCGTGCAGCAGGGCGACTACGAGAAGTTCAAGGAATACACCGCGCTGGTGGACCAGCGCCCAGTGTCGATGATCCGCGACCTGTTGCAGGTGAAGACCGCCGCGCAGCCGCTGGCGCTCGACGAGGTGGAGCCGCTGGAAGCCATCTTCAAGCGCTTCGATGCCGCCGGGATTTCCCTCGGCGCGCTGTCGCCGGAGGCCCACGAGGCGCTGGCCGAGGCGATGAACACCCTGGGCGGTCGCTCCAACTCCGGCGAGGGCGGCGAGGACCCGGCGCGCTACGGCACGTTGAAGAGTTCGAAGATCAAGCAGGTGGCTACCGGCCGCTTCGGCGTGACCCCGGAATACCTGGTCAACGCCGAGGTCCTGCAGATCAAGGTGGCCCAGGGTGCCAAGCCCGGCGAGGGCGGCCAGTTGCCGGGCGGCAAGGTCAACGGCCTGATCGCCCGCCTGCGCTATGCGGTGCCCGGCGTGACCCTGATCTCGCCGCCGCCGCACCACGACATCTACTCCATCGAAGACCTGGCGCAGCTGATCTTCGACCTCAAGCAGGTCAACCCGCAGGCGCTGGTATCGGTGAAGCTGGTATCCGAGCCGGGCGTCGGCACCATCGCCGCCGGCGTGGCCAAGGCCTATGCGGACCTGATCACCATCTCCGGCTACGACGGCGGTACCGGCGCCTCGCCGATCACCTCGATCAAGTACGCCGGCTCGCCCTGGGAACTGGGCCTGGCGGAAACCCACCAGACCCTGCGCGGCAACGACCTGCGCGGCAAGGTCCGGGTGCAGACCGATGGCGGCCTGAAGACAGGCCTGGACGTGATCAAGGCGGCCATTCTCGGCGCCGAGAGCTTCGGCTTCGGCACCGCGCCGATGATCGCCCTGGGCTGCAAGTACCTGCGCATCTGCCATCTGAACAACTGCGCCACCGGCGTGGCGACGCAGAACGACAAGTTGCGCAAGGACCACTTCATCGGCACCACCGCGATGGTGATCAACTTCTTCACCTTCATCGCCACGGAAACCCGCGAGTGGCTGGCGCGCCTCGGCGTGCGCAGCCTGGGCGAGCTGATCGGCCGCACCGACCTGCTGGAGATCCTCCCCGGCGAGACCGCCAAGCAGCAGAACCTGGATCTCGCTCCGTTGCTGGGCAGTGAGCTGATCCCGGCCGACAAGCCGCAGTTCTGCGAGGTGGAGAAAAACCCGCCGTTCGACCAGGGCCTGCTGGCCGAGAAGATGGTCGAGCTGTCGAAGGCCGCCATCGAAGGCCTGAGCGGCGGCGAGTACGAGCTGGACATCTGCAACTGCGACCGATCCATCGGCGCGCGGGTATCCGGCGAGATCGCCCGCCTGCACGGCAACCAGGGCATGGCCAAGGCACCGGTGGTGTTCCGTTTCAAGGGCACCGCGGGACAGAGCTTCGGCGTGTGGAACGCCGGTGGCCTGCACCTGTACCTGGAAGGCGACGCCAACGACTACGTAGGCAAGGGCATGACCGGCGGCAAGCTGGTGATCACCCCGCCCAAGGGCAGTCCGTTCAAGACCCAGGAATCGGCCATCGTCGGCAACACCTGCCTGTACGGCGCCACCGGCGGCAAGCTGTTCGCCGCCGGAACCGCCGGCGAGCGCTTCGCCGTGCGCAACTCCGGTTCCCATGCGGTGGTGGAAGGTACCGGCGACCACTGCTGCGAATACATGACCGGCGGTTTCGTCTGCGTGCTGGGCAAGACCGGCTACAACTTCGGCTCCGGCATGACCGGGGGCTTCGCCTACGTCCTCGACATGGACAACACTTTCGTCGACCGCGTGAACCACGAGCTGGTGGAAATCCAGCGGATCAGCGGCGAGGCGATGGAGGCCTATCGCAGCCACCTGCGCAAGGTCCTGGTCGAGTACGTGAACGAAACGGCAAGCGAGTGGGGCGCGAACATCCTGGAAAACCTGGATGACTACCTGCGTCGGTTCTGGCTGGTGAAACCGAAGGCGGCCAGCCTCGGTTCGCTGCTGACCAGCACCCGTGCCAACCCGCAATAA |
| Protein Properties |
| Protein Residues: |
1481 |
| Protein Molecular Weight: |
161.6 kDa |
| Protein Theoretical pI: |
6.03 |
| Hydropathicity (GRAVY score): |
-0.143 |
| Charge at pH 7 (predicted): |
-19.3 |
| Protein Sequence: |
>PA5036
MKAGLYHPETFKDNCGFGLIAHMQGEPSHQLLQTAIEALTCMTHRGGINADGKTGDGCGLLIQKPDLFLRAVAREAFSVDLPEQYAVGMVFFNQDPVKAEAARENMNREIVAAGLELVGWRKVPIDTSVLGRLALERLPQIEQVFIGGAGLSDQDFAIKLFSARRRSSVANAADSDHYICSFSHKTIIYKGLMMPADLAAFYPDLGDERLQTAICVFHQRFSTNTLPKWPLAQPFRFLAHNGEINTITGNRNWAQARRTKFTNELIPDLEELGPLVNRVGSDSSSMDNMLELMVTGGMDLFRGLRMIIPPAWQNVETMDADLRAFYEYNSLHMEPWDGPAGVVLTDGRYAVCLLDRNGLRPSRWVTTKNGYITLASEIGVWDYKPEDVIAKGRVGPGQILAVDTETGQVLHSDDIDNRLKSRHPYKQWLRQNALRIQATLDDDHGVASYDADQLKQFMKMFQVTFEERDQVLRPLGEQGQEAVGSMGDDTPMAILSRRIRSPYDYFRQQFAQVTNPPIDPLREAIVMSLETCLGVEQNIFEEAPHHANQAILTTPVISPAKWRTIMTLDRPGFDRHFIDLNYDESMGLEAAVRNIADQAEEAVRGGKVLLILSDRHIAPGKLPVHAALAVGAVHHRLVQTGLRCDSNILVETATARDPHHFAVLIGFGASAVYPFLAYEVLADLIRTGEVLGDLYEVFKYYRKGISKGLMKILSKMGISTVASYRGAQLFEAVGLSDEVTDLCFTGVASRIQGARFVDIENEQKLLAAEAWSNRKPIQQGGLLKFVYGGEYHAYNPDVVNTLQAAVQQGDYEKFKEYTALVDQRPVSMIRDLLQVKTAAQPLALDEVEPLEAIFKRFDAAGISLGALSPEAHEALAEAMNTLGGRSNSGEGGEDPARYGTLKSSKIKQVATGRFGVTPEYLVNAEVLQIKVAQGAKPGEGGQLPGGKVNGLIARLRYAVPGVTLISPPPHHDIYSIEDLAQLIFDLKQVNPQALVSVKLVSEPGVGTIAAGVAKAYADLITISGYDGGTGASPITSIKYAGSPWELGLAETHQTLRGNDLRGKVRVQTDGGLKTGLDVIKAAILGAESFGFGTAPMIALGCKYLRICHLNNCATGVATQNDKLRKDHFIGTTAMVINFFTFIATETREWLARLGVRSLGELIGRTDLLEILPGETAKQQNLDLAPLLGSELIPADKPQFCEVEKNPPFDQGLLAEKMVELSKAAIEGLSGGEYELDICNCDRSIGARVSGEIARLHGNQGMAKAPVVFRFKGTAGQSFGVWNAGGLHLYLEGDANDYVGKGMTGGKLVITPPKGSPFKTQESAIVGNTCLYGATGGKLFAAGTAGERFAVRNSGSHAVVEGTGDHCCEYMTGGFVCVLGKTGYNFGSGMTGGFAYVLDMDNTFVDRVNHELVEIQRISGEAMEAYRSHLRKVLVEYVNETASEWGANILENLDDYLRRFWLVKPKAASLGSLLTSTRANPQ |
| References |
| External Links: |
|
| General Reference: |
PaperBLAST - Find papers about PA5036 and its homologs
|